How to build an Apache Spark Batch Job
1. Overview
This tutorial will give an introduction to Apache Spark and all its components, and provide a step-by-step explanation of how to implement a Spark Batch Job to process a big data input, here you will be able to checkout our repository
2. Apache Spark
Apache Spark is an open-source unified analytics engine for large-scale data processing. Spark provides an interface for programming clusters with implicit data parallelism and fault tolerance. Originally developed at the University of California, Berkeley's AMPLab, the Spark codebase was later donated to the Apache Software Foundation, which has maintained it since.
Apache Spark has its architectural foundation in the resilient distributed dataset (RDD), a read-only multiset of data items distributed over a cluster of machines, that is maintained in a fault-tolerant way. The Dataframe API was released as an abstraction on top of the RDD, followed by the Dataset API. In Spark 1.x, the RDD was the primary application programming interface (API), but as of Spark 2.x use of the Dataset API is encouraged even though the RDD API is not deprecated. The RDD technology still underlies the Dataset API.
Spark and its RDDs were developed in 2012 in response to limitations in the MapReduce cluster computing paradigm, which forces a particular linear dataflow structure on distributed programs: MapReduce programs read input data from disk, map a function across the data, reduce the results of the map, and store reduction results on disk. Spark's RDDs function as a working set for distributed programs that offers a (deliberately) restricted form of distributed shared memory.
Inside Apache Spark the workflow is managed as a directed acyclic graph (DAG). Nodes represent RDDs while edges represent the operations on the RDDs.
Spark facilitates the implementation of both iterative algorithms, which visit their data set multiple times in a loop, and interactive/exploratory data analysis, i.e., the repeated database-style querying of data. The latency of such applications may be reduced by several orders of magnitude compared to Apache Hadoop MapReduce implementation. Among the class of iterative algorithms are the training algorithms for machine learning systems, which formed the initial impetus for developing Apache Spark.
Apache Spark requires a cluster manager and a distributed storage system. For cluster management, Spark supports standalone (native Spark cluster, where you can launch a cluster either manually or use the launch scripts provided by the install package. It is also possible to run these daemons on a single machine for testing), Hadoop YARN, Apache Mesos or Kubernetes. For distributed storage, Spark can interface with a wide variety, including Alluxio, Hadoop Distributed File System (HDFS), MapR File System (MapR-FS), Cassandra, OpenStack Swift, Amazon S3, Kudu, Lustre file system, or a custom solution can be implemented. Spark also supports a pseudo-distributed local mode, usually used only for development or testing purposes, where distributed storage is not required and the local file system can be used instead; in such a scenario, Spark is run on a single machine with one executor per CPU core.
2. Apache Spark Components
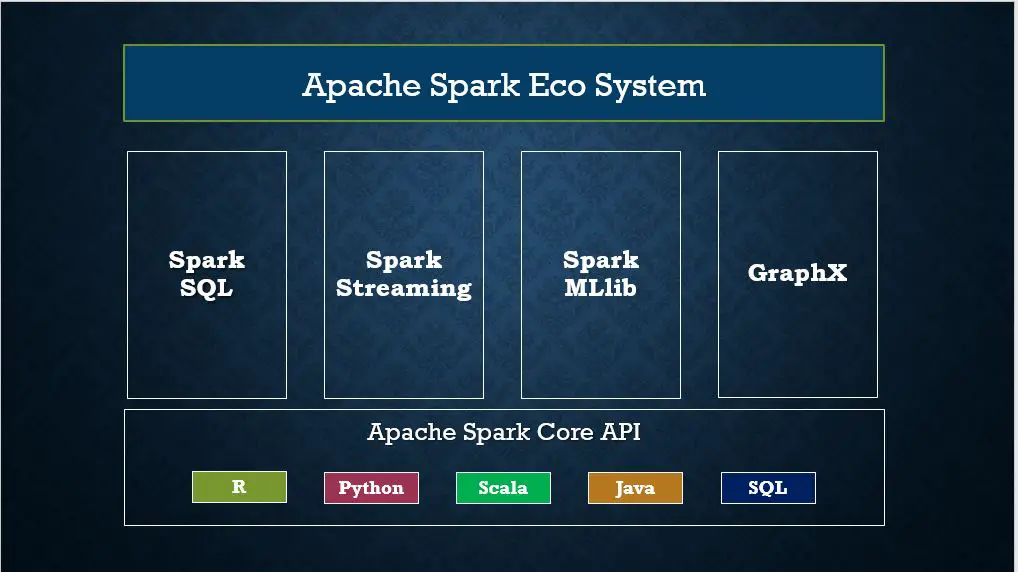
-
Spark Core
Is the foundation of the overall project. It provides distributed task dispatching, scheduling, and basic I/O functionalities, exposed through an application programming interface (for Java, Python, Scala, .NET[16] and R) centered on the RDD abstraction (the Java API is available for other JVM languages
-
Spark SQL
Is a component on top of Spark Core that introduced a data abstraction called DataFrames,[a] which provides support for structured and semi-structured data. Spark SQL provides a domain-specific language (DSL) to manipulate DataFrames in Scala, Java, Python or .NET. It also provides SQL language support, with command-line interfaces and ODBC/JDBC server. Although DataFrames lack the compile-time type-checking afforded by RDDs, as of Spark 2.0, the strongly typed DataSet is fully supported by Spark SQL as well
-
Spark Streaming
Uses Spark Core's fast scheduling capability to perform streaming analytics. It ingests data in mini-batches and performs RDD transformations on those mini-batches of data. This design enables the same set of application code written for batch analytics to be used in streaming analytics, thus facilitating easy implementation of lambda architecture.
-
MLlib Machine Learning Library
Spark MLlib is a distributed machine-learning framework on top of Spark Core
-
GraphX
Is a distributed graph-processing framework on top of Apache Spark. Because it is based on RDDs, which are immutable, graphs are immutable and thus GraphX is unsuitable for graphs that need to be updated, let alone in a transactional manner like a graph database
3. Spark Batch Job
A Spark Batch Job, is an application that will take a large information input and process its data, normally this input is Big Data, since the main objective for Spark Job is tacking the advatage of the distributed processing capabilities provided by Hadoop environment to process large datasets, is the perfect tool to have in any big data processing data pipeline
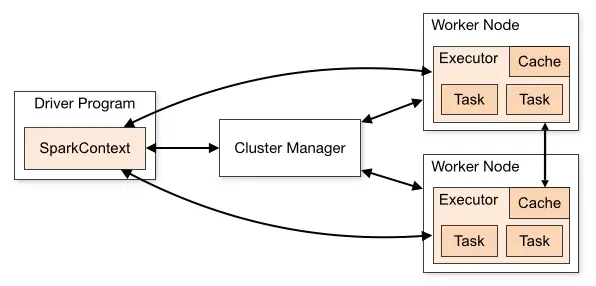
Architecture
Apache Spark works in a master-slave architecture where the master is called “Driver” and slaves are called “Workers”. When you run a Spark application, Spark Driver creates a context that is an entry point to your application, and all operations (transformations and actions) are executed on worker nodes, and the resources are managed by Cluster Manager.
Language Compatibility
Spark runs on Java 8/11/17, Scala 2.12/2.13, Python 3.7+ and R 3.5+. Java 8 prior to version 8u201 support is deprecated as of Spark 3.2.0. When using the Scala API, it is necessary for applications to use the same version of Scala that Spark was compiled for. For example, when using Scala 2.13, use Spark compiled for 2.13, and compile code/applications for Scala 2.13 as well. please click here for more details
4. Creating the spark context
The spark job will require a context in order to connect to the cluster so the driver program will send the instructions, in this example we set the job name with appName and defined we use the stand alone local cluster using master = local[*]
val spark = SparkSession
.builder
.appName("SparkScalaLogsAnalyzerJob")
.master("local[*]")
.getOrCreate()
5. Loading the Data into a RDD
In this example we are trying to process the access logs from a web server which is a perfect candidate for big data since this is a huge behavioural data set, since this is a text file we use textFile from the spark context to load the text file into our RDD, however, this would be placed to load files from Amazon S3 or other cloud sources
val lines = spark.sparkContext.textFile("data/access_log")
6. Working with RDDs
Once the data is loaded we can start to map the lines into a data structure, we can filter or make any kind of processing
val accessEntriesRdd = lines.flatMap(httpAccessEntryMapper.map(_))
7. Working with SparkSQL
Since we have loaded our RRD we can easily transform it into a DataSet where we can execute SQL queries, therefore having the data on a DataSet, we make a groupBy and apply a count as we were working with SQL
import spark.implicits._
val accessEntriesDs = accessEntriesRdd.toDS()
val ipAddressCountDs = accessEntriesDs.groupBy("ipAddress").count()
8. Storing the results of the processing
Once we have finished to work with our DataSet we can save this in many formats such as Parquet, JSON, CSV, SQL Database, Amazon S3 ...
ipAddressCountDs.write.csv("out/ipcount.csv")
9. Stop the Driver
And after data have been saved, we can terminate the Driver program
spark.stop()
10. Source Code
Checkout the whole source code from our repository